🧧 It was Chinese New Year Eve.
While most people were out visiting relatives, sitting around round tables performing the annual ritual of togetherness, I stayed in my cave.
Not out of sadness. Not out of rebellion. Just preference.
My energy was low that day. The kind of low where you don’t want to start anything serious but you also don’t want to do nothing. 🎮 So I picked something small, almost trivial: building my own addon for World of Warcraft.
With the Midnight expansion, Blizzard overhauled large parts of the addon API. A lot of addons broke. The old Macro Manager I used to rely on? Gone. The default UI? Still unbearable. I have never truly played with default UI since day one. This was just another reminder why.
I searched for alternatives for hours. Found none.
So I thought: why not make one?
Not because it matters.
Not because it advances my career.
Just because it irritated me enough.
🎵 Building in the Dark
I started the way most people would now: raw prompts.
Zero knowledge of the WoW API. Just describing what I wanted. ❌ It failed. Completely.
This wasn’t web development. The AI had no training data for WoW’s addon API. It hallucinated functions, repeated patterns, confidently produced things that simply did not work.
So I grabbed Blizzard’s official UI source code from 📝Gethe‘s GitHub mirror. Blizzard doesn’t host these files publicly, you have to extract them manually from the game client every patch.
Without Gethe’s automated extraction, the community wouldn’t have an easy way to reference how Blizzard actually builds their UI. Files like Blizzard_MacroUI.lua and Blizzard_MacroUI.xml. I fed them directly into the prompt as reference material.
And then, something happened.
✨ The first workable version was born.
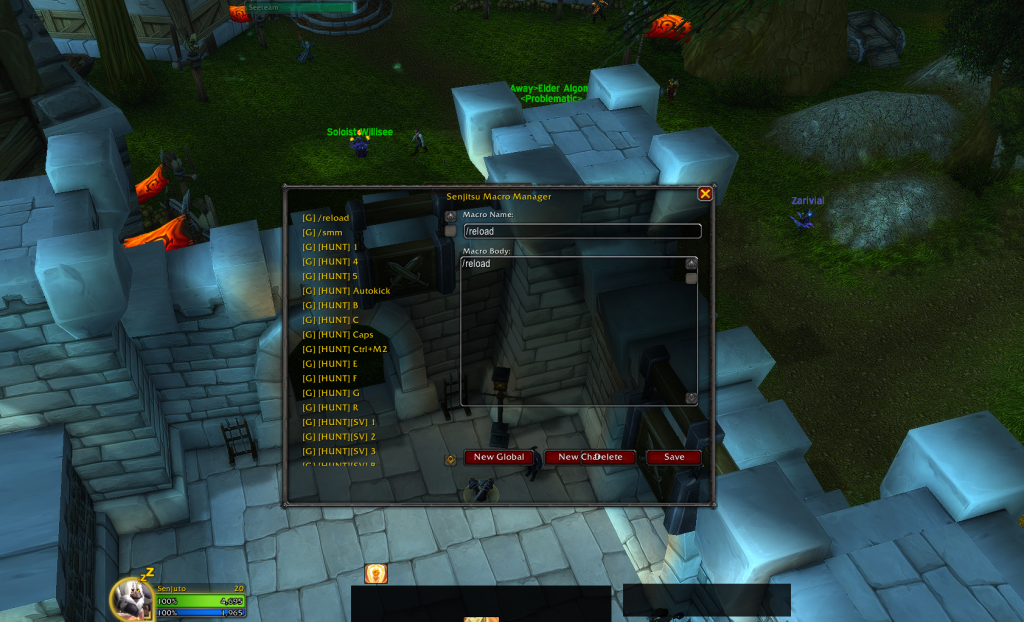
A main window. A scrollable list on the left showing all my macros, both General (120 slots) and Character-specific. Click one, and the right side populates with its name, icon, and body text. Edit it. Save it. It worked.
The core CRUD operations were there: Create, Read, Update, Delete. All using WoW’s native API calls GetMacroInfo, EditMacro, CreateMacro. No XML. Pure Lua. Event-driven through UPDATE_MACROS.
That moment felt real.
But the code was a disaster.
One massive file. Sequential execution. Functions doing five things at once. The kind of mess you get when you’re stitching together AI outputs without a map.
It worked. But I didn’t own it.
🏗️ From Chaos to Structure
Here’s where the engineer in me kicked in.
I couldn’t leave it like that. Not because of pride, because I knew this mess would collapse the moment I tried to extend it.
So I switched modes.
🗺️ Step 1: Define the lifecycle
I asked AI to map out the addon’s lifecycle. Not to write code, but to think architecturally. What are the phases? Initialization. Layout calculation. UI creation. Event registration. Refresh logic.
🦴 Step 2: Create the skeleton
I created empty functions following Single Responsibility Principle:
InitializeLayout(): calculate dimensionsCreateListView(): build the macro listCreateDetailView(): build the editor paneRefreshList(): sync UI with game stateSetFormMode(): manage create/edit states
Each function had one job. Clear boundaries.
🔧 Step 3: Port the mess, piece by piece
Then I asked AI to migrate the existing code into these functions. Step by step. Test-driven. After each migration, I loaded the addon in-game to verify nothing broke.
🔍 Step 4: Code review with thinking models
Finally, I ran my custom code review prompt through Claude Opus 4.6 thinking mode. Powerful enough to catch the vibe-coded mess I couldn’t see.
It flagged:
- Poor variable names (check for scroll position, X/Y for columns/rows)
- Magic numbers scattered everywhere (60, 200, 134400, 120)
- Dead code (unused variables, no-op self mappings)
- DRY violations (duplicated limit checks, pool patterns)
I fixed them. Not blindly, I read each finding, understood the issue, then decided how to address it.
The result:
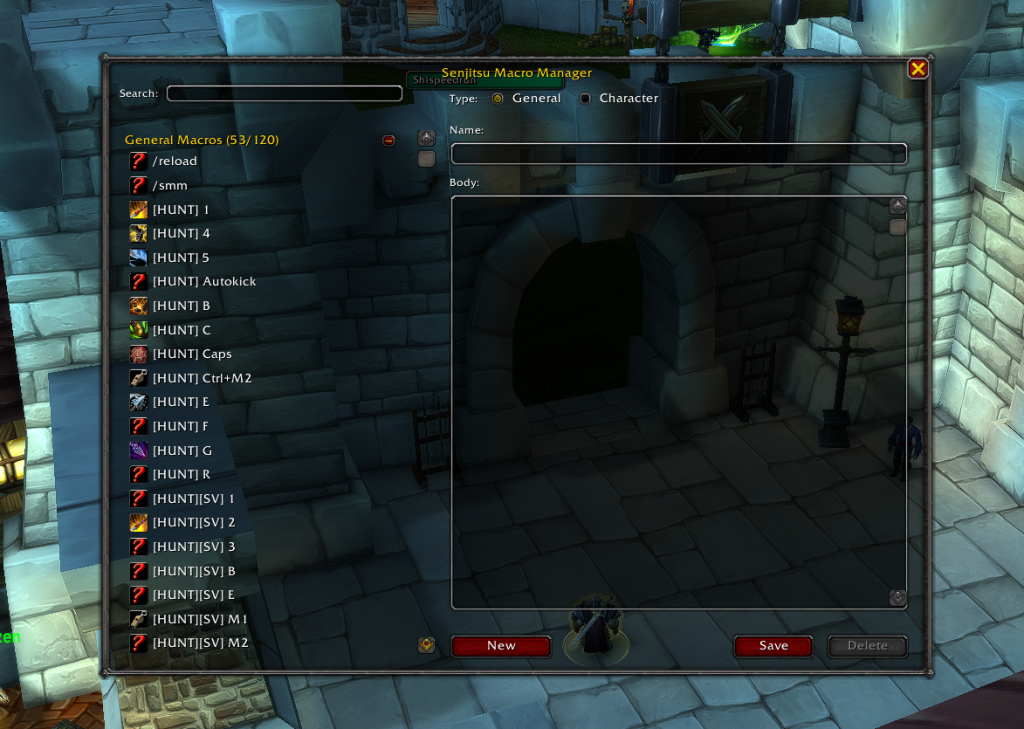
and finally, a polished and complete version
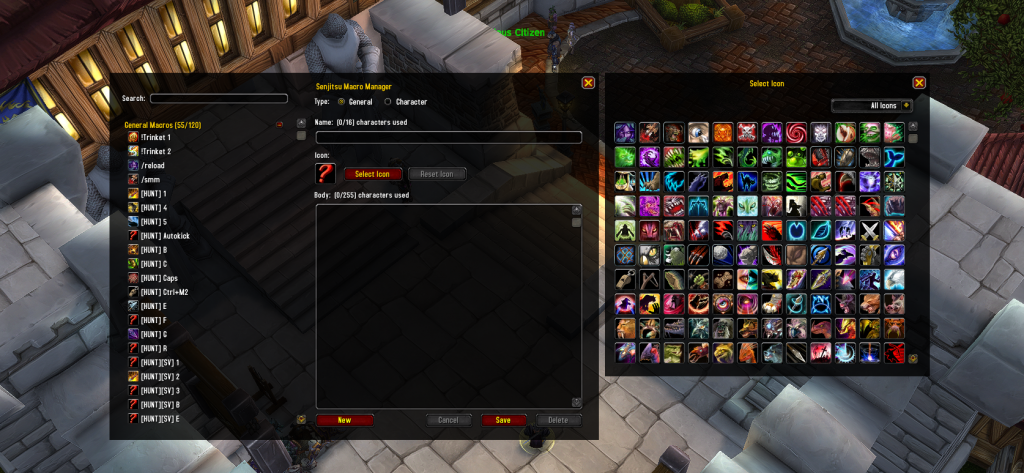
A clean, modular architecture. Responsive layout system that adapts to screen size. Search/filter with real-time updates. Collapsible groups. Icon browser with 120 icons in a scrollable grid. Type swapping between General and Character macros. Drag support to action bars.
All of this without understanding frame anchoring, backdrop templates, or WoW’s event system at the start.
🚪 AI lowered the activation threshold.
But structure? That still required an architect’s mindset.
🎮 The Missing Piece: Control
As a senior engineer, I’m used to being inside the system.
When something breaks, I don’t guess, I trace.
I don’t retry randomly, I redefine the problem.
I don’t ask for miracles, I narrow the search space.
This time was different.
Even after the refactor, I still didn’t fully understand the code.
I couldn’t tell you why BackdropTemplate needed to be explicitly mixed in, or why the Icon Browser had to be anchored TOPRIGHT to move with the main frame. I didn’t mentally simulate the frame lifecycle. If a deep bug appeared (say, taint issues or combat lockdown), I wouldn’t know where to begin. 🤷
And when AI gets stuck, it spirals. It repeats. It cycles through variations of the same flawed assumption. Normally I would step in and redirect it. But without understanding the API, I couldn’t.
The relationship shifted.
I was no longer a collaborator inside the system.
📋 I was more like a manager reviewing output from a contractor.
That detachment is new to me.
The dopamine rush was real. The speed was real. The structure was real. But the grounded feeling, the deep confidence that I could debug anything, was not.
🚫 A Line I Would Not Cross
But here’s the important boundary.
This addon is a toy. A private experiment. A curiosity.
I would never ship this approach into production.
I would never sell something I don’t fully understand.
I would never take responsibility for a system I cannot debug.
Because
Production is not about “it works.”
Production is about: I can carry the consequences. ⚖️
That line is clear to me.
There is a difference between experimental creation and accountable engineering.
🔀 Two Modes of Creation
What I experienced that day wasn’t an identity crisis. It was exposure to a new mode of creation.
There is:
- 🐢 Deep engineering: slow, controlled, fully understood.
- 🚀 AI-accelerated exploration: fast, partially opaque, low commitment.
For a side quest on a holiday? The second mode is liberating.
For real responsibility? It is not enough.
But here’s what I learned: you can blend them.
- Use AI to cross the activation threshold
- Apply engineering discipline to impose structure
- Use thinking models to audit the mess
- Test-driven migration to maintain stability
The result isn’t full mastery. But it’s closer to ownership than raw vibe coding.
Maybe that’s the adjustment AI demands from engineers: not surrendering control, but knowing when full control is necessary.
Some creations don’t need to be completely understood to exist.
But the moment they enter production, they must be.
🎯 And knowing the difference might be the real skill.
🛠️ What’s Next
The addon works. I use it daily. The structure is clean. But I don’t fully own it yet.
Next steps:
- Understand frame anchoring: Why does
TOPRIGHTpositioning make the Icon Browser move with the main frame? - Learn backdrop templates: Why does
BackdropTemplateneed explicit mixin calls? - Study the event system: How does
UPDATE_MACROSpropagate through the UI lifecycle? - Master taint mechanics: What triggers combat lockdown and how do secure frames actually work?
The goal isn’t to abandon AI. It’s to close the gap between “it runs” and “I can carry it.”
Because that’s when a side project becomes real engineering.